VMware just released VMware Cloud Foundation (VCF) 4.3 and I have several customers planning to upgrade in the near future, so I decided to upgrade my lab to get some experience. I also have two customers planning to deploy VCF 4.3 on new hardware so I will also soon deploy it from scratch to see what’s new with the bring-up procedure. VCF 4.3 comes with a lot of fixes and new features that you can read about in the Release Notes.
My current VCF lab is running version 4.2 and consist of one Management Workload Domain (WLD) with one Stretched Cluster. That is two Availability Zones with four ESXi hosts in each and a vSAN Witness running in a third independent site. In addition, I have one VI Workload Domain (WLD) containing three ESXi hosts in a non-stretched Cluster. Currently I don’t run vRealize Suite, Tanzu or anything else than what is included in the VCF base-platform. Everything is deployed using VLC.
I started by reading the Release Notes and the Upgrading to VMware Cloud Foundation 4.3 docs, as well as a few blog posts about what is new in this release.
The following steps were then performed to upgrade VCF to version 4.3. Note that all images are clickable to make them bigger.
First I did a quick health check of my environment by logging into the vSphere Client and SDDC Manager and looked for any alarms or warnings. It was surprisingly healthy.


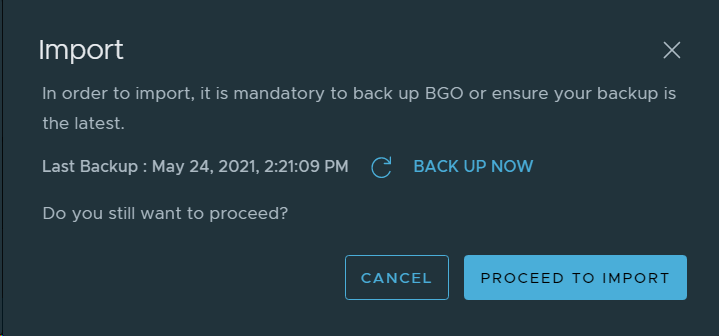
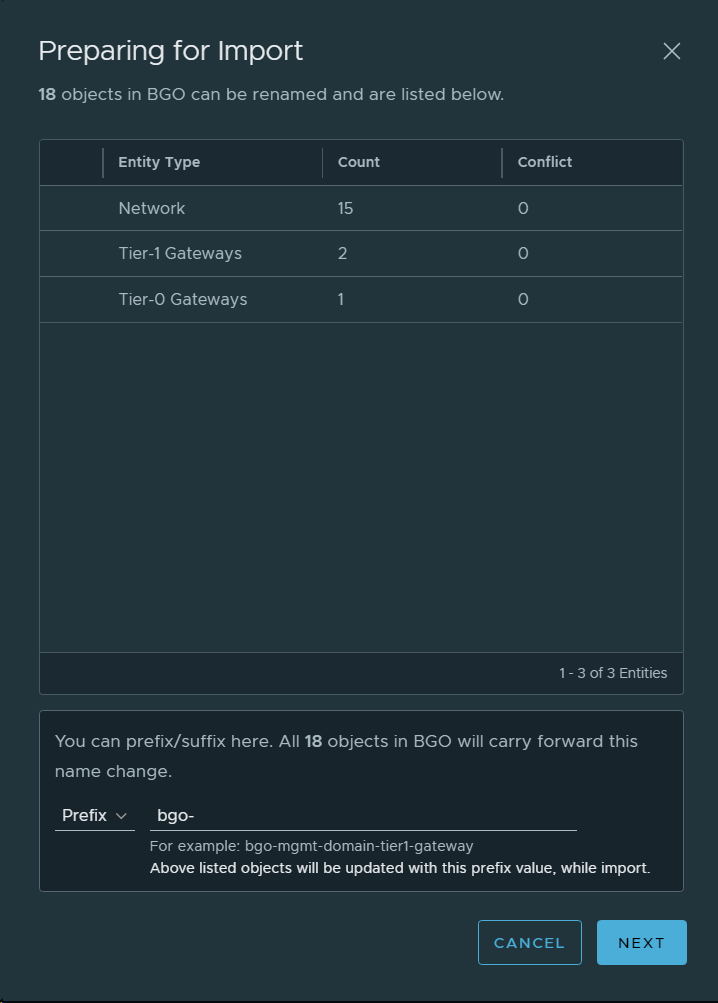
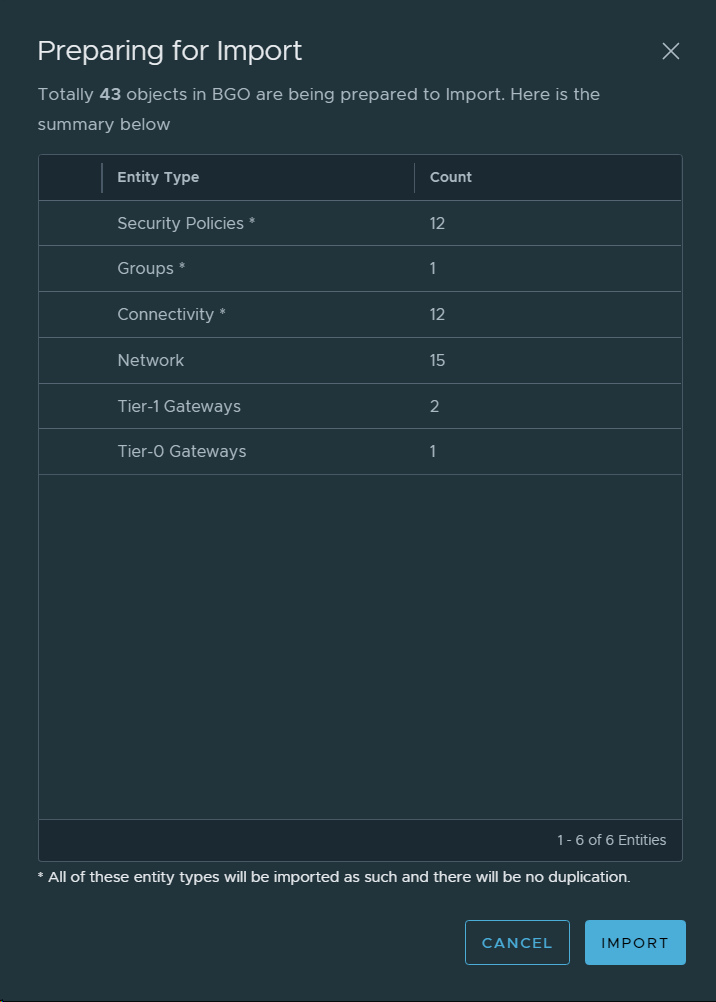
Then I checked that I was actually running on version 4.2, and verified that there was an update available for the Management WLD. I also selected to download both required upgrade bundles.

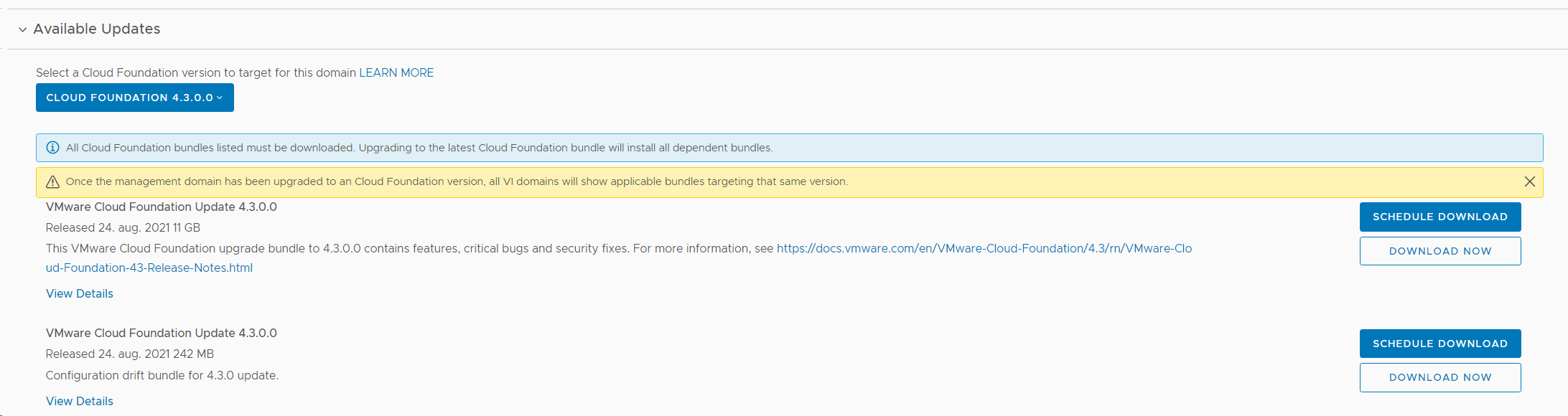
Ran an Update Precheck to ensure that my environment was ready for the update. It passed successfully, but I had already implemented a fix to skip vSAN HCL Checks for ESXi Upgrades since I am running on nested ESXi hosts, or else it would have failed.

Installed the VCF 4.3 update.

Went back to the Patches/Updates section for the Management WLD and found that the NSX-T 3.1.3 update was available, so I chose to download and install that.

I chose to upgrade both my Edge Clusters and my Host Clusters in one go, but there is an option to upgrade them separately starting with the Edge Clusters. You can also choose between parallell or sequential upgrades, and I went for the default which is parallell even though it wouldn’t matter in my case since I only have one cluster of each type.

When the update starts, you can see status on each component it is updating.
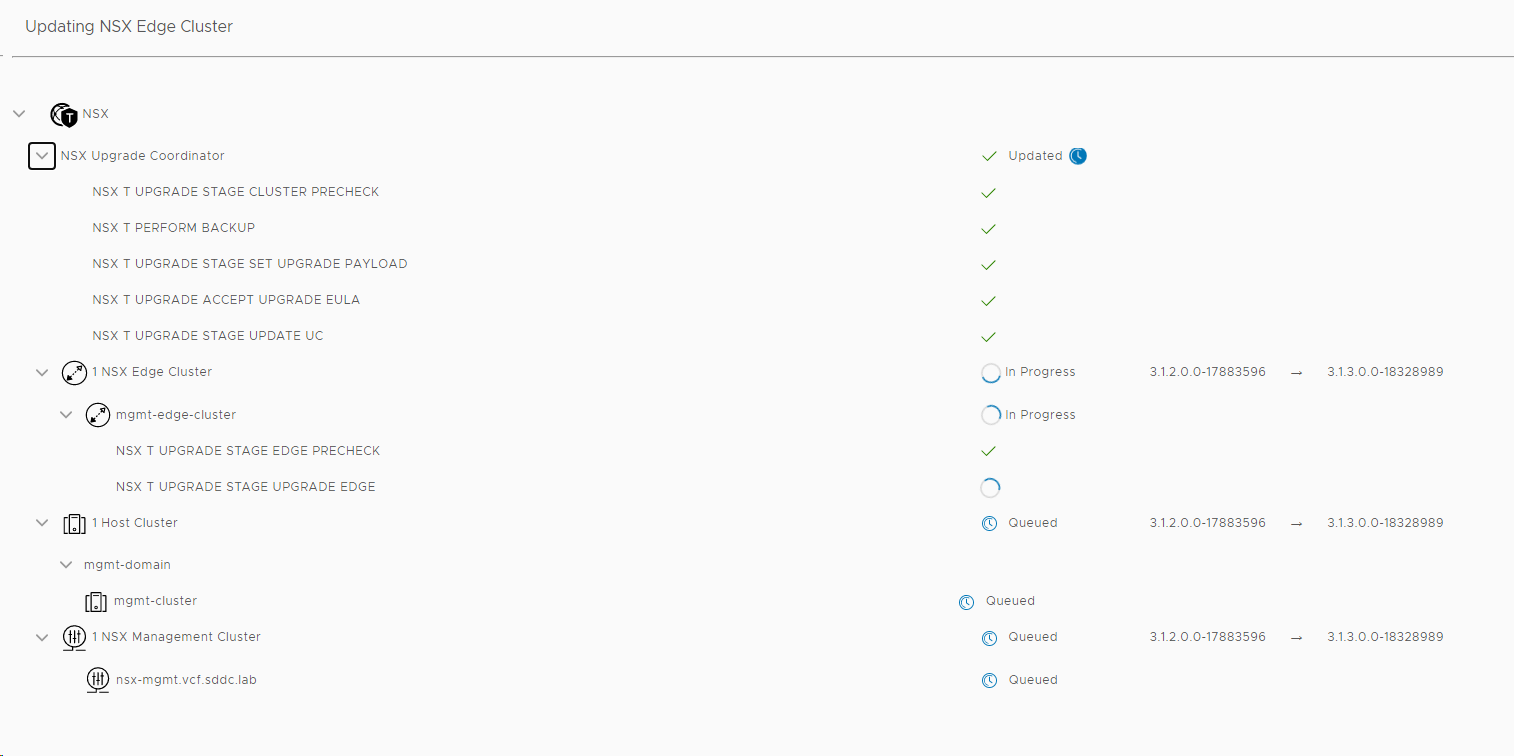
You can also select VIEW UPDATE ACTIVITY to get more details on what it is doing.

Next available update was for vCenter Server so I downloaded and installed that.

When vCenter was done upgrading, ESXi 7.0 Update 2a was downloaded and installed.

I selected to enable Quick Boot to speed up the upgrade of ESXi. Note that your hardware must support this feature if you are running on bare-metal instead of nested ESXi like I do.
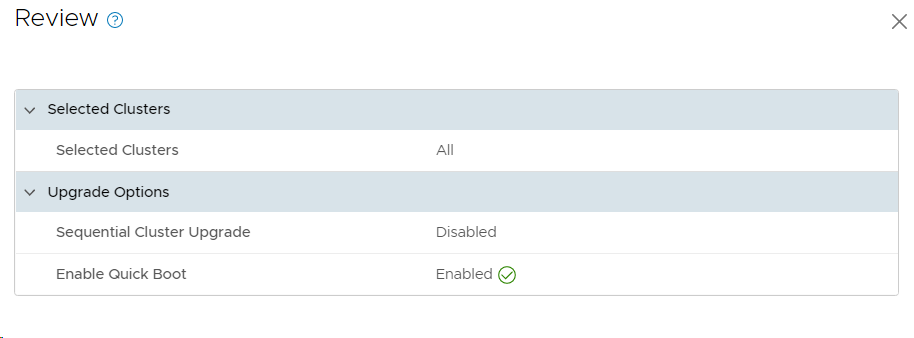
The ESXi update got cancelled for some reason, so I retried to install it, but it got cancelled again.

I ran a new Precheck and found that VUM had problems uploading the patch files to the four ESXi hosts in AZ2.

Looking at the logs on one of the hosts showed me that it didn’t have enough memory. These four hosts only had 16 GB RAM each, so I increased this to 64 GB to make them equal to the hosts in AZ1.
I ran the Precheck again and this time it succeeded.

I tried to install the ESXi update again, but it got cancelled this time too. Rerunning the Precheck now showed that NTP was out of sync between my PSC and my SDDC Manager. However, when manually checking I found that this was not the case. The error didn’t specify which PSC so I started suspecting it could be due to my VI WLD vCenter appliance was down. After starting that up again, this NTP out of sync error disappeared and the Precheck went through all green. It would be nice if the Precheck was able to tell me which PSC it was complaining about, and also tell me that NTP wasn’t the problem, but that it didn’t have connectivity to it at all.
I tried to install the ESXi upgrade again, but it still got cancelled without giving me any reason. Digging through the /var/log/vmware/vcf/lcm/lcm.log file on SDDC Manager gave me this hint:
2021-09-01T09:36:55.684+0000 WARN [vcf_lcm,801535c71a337889,d768] [c.v.evo.sddc.lcm.orch.Orchestrator,pool-7-thread-6] Cannot start upgrades since there are pending or, failed workflows
I looked into my Tasks list in SDDC Manager and found several failed tasks, but one stood out as not being resolved. SDDC Manager had tried to rotate the passwords, but were unable to do so on my VI WLD vCenter and NSX Manager since they were turned off temporarily. I went into Password Management and found an error there saying the same thing, and hitting retry solved this issue without problems since all appliances were back up running now.
I went back to Updates/Patches for my Management WLD and retried to install the ESXi update, and this time it started running. So even though the Precheck is all green you can still have issues causing the upgrade to be cancelled without any useful message in the user interface. The Upgrade Prerequisites tells us to “Ensure that there are no failed workflows in your system”, but in my lab there is usually a few failed tasks which are stuck without blocking an upgrade. It is also not a good idea to shut down appliances in other WLDs to save resources during an upgrade.
None of these problems would happen in a production environment since they were all caused by lack of resources in my nested lab.
Checked the VCF version again, and this time it said 4.3!

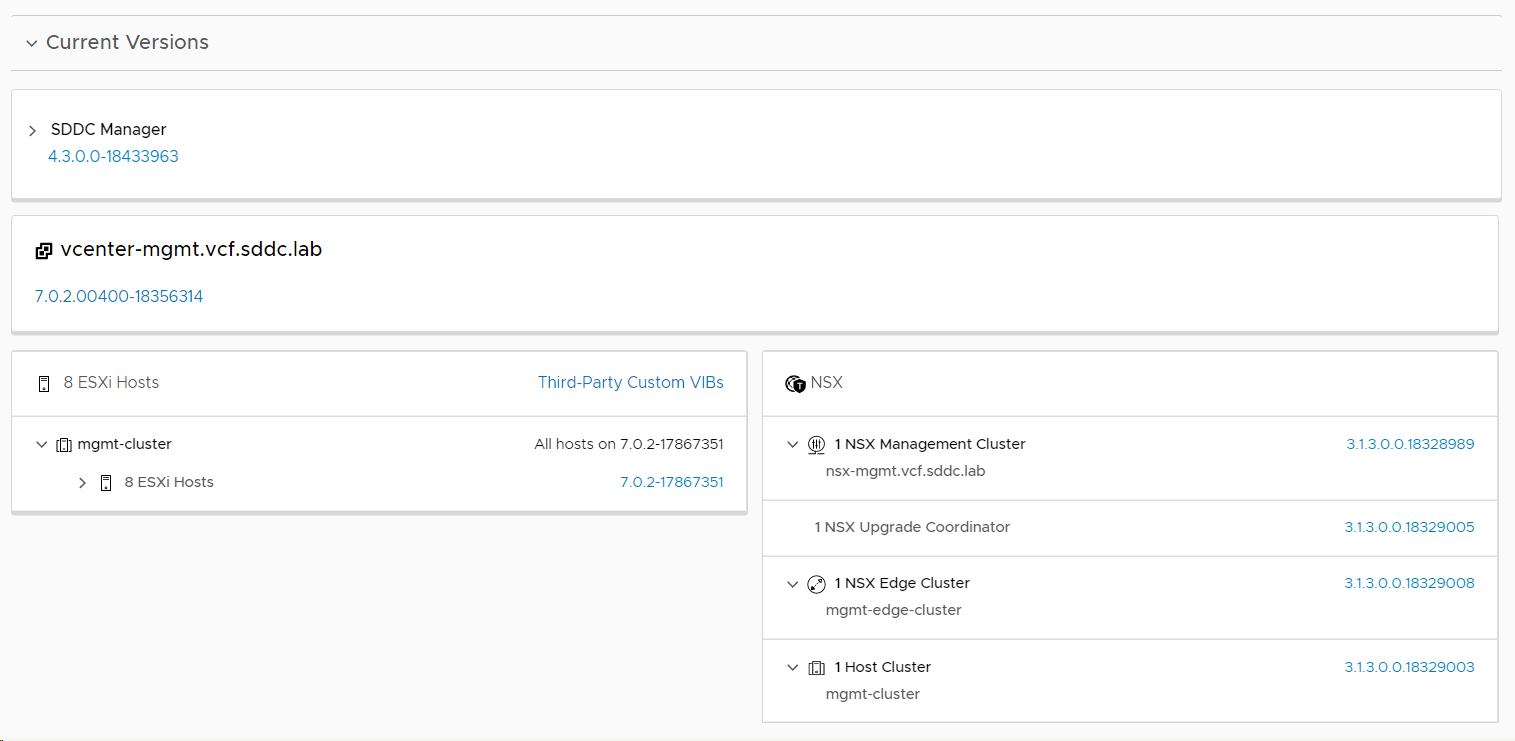
The last two things to update was the vSAN Disk format version and the ESXi version on my vSAN Witness Appliance, which SDCC Manager doesn’t care about upgrading, which is a bit disappointing. I used vSphere Lifecycle Manager to patch the vSAN Witness Appliance to the same build as my ESXi hosts. vSAN Disk format is also upgraded in the vSphere Client.
I must admit that upgrading VCF in my lab usually gives me some trouble along they way, but most of the time it is caused by some component lacking resources. It tends to be fixed by increasing CPU, memory or disk resources for either vCenter or NSX-T Manager appliances. I have also had issues were ESXi hosts were unable to enter/exit maintenance mode, caused by admission control or a blocking VM.
If time permits, I will soon post about how I deploy VCF 4.3 from scratch with focus on what is new regarding the bring-up, as well as presenting some of the new features in VCF 4.3.